피클파일로 저장했던 데이터프레임을 그대로 가져와서, dtypes로 데이터타입까지 잘 가져와졌는지 점검합니다. 수치데이터가 들어간 칼럼들은 float 혹은 int로 잘 저장되어 왔네요.
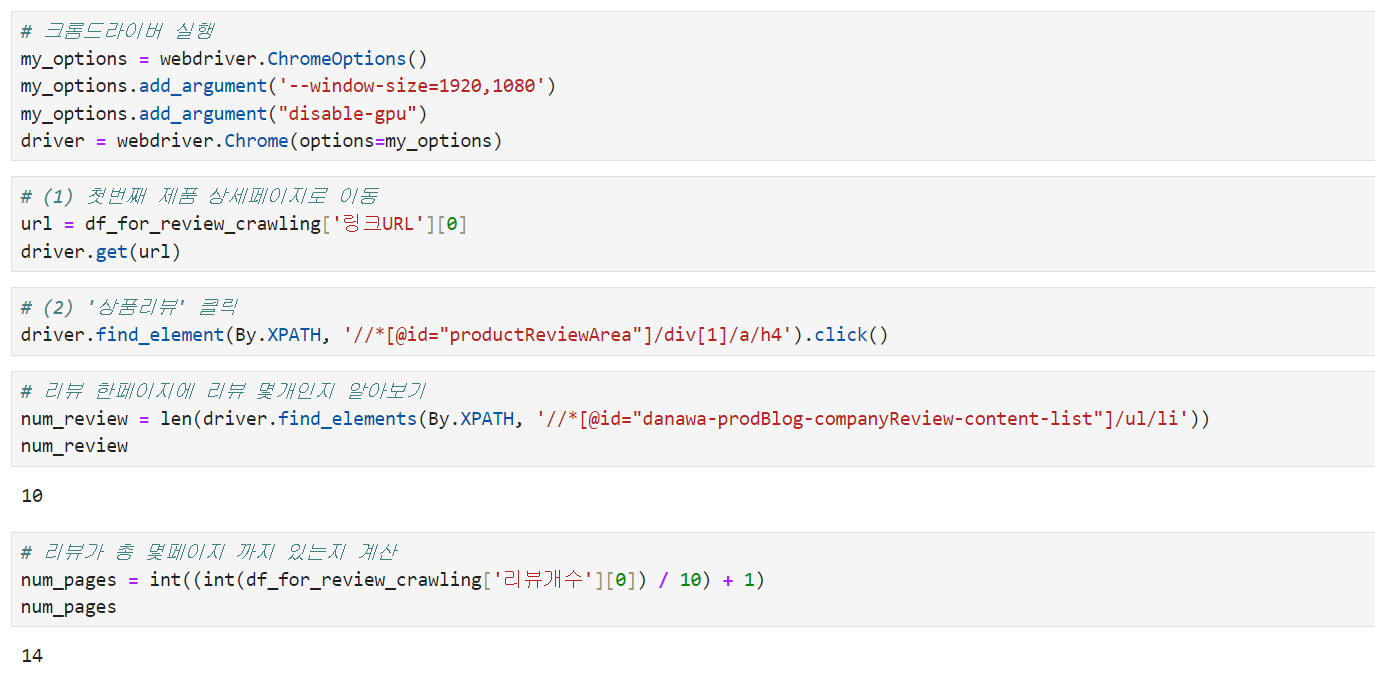
1️⃣ 제품별 상세페이지로 들어간 다음, 리뷰 페이지를 넘기면서 크롤링해오려고 합니다.
제품별로 상세페이지 URL을 수집했었죠! 이제 이 URL에 순서대로 접속해서 리뷰를 크롤링해오겠습니다.
상세페이지 URL 접속 → 상품리뷰로 이동 → 리뷰 페이지 넘기면서 → 페이지 소스 가져오기 흐름으로 구성해볼게요.
일단 맨 첫번째 제품으로 테스트를 해보겠습니다.
리뷰 페이지 넘기면서 긁어오는 과정은 이전포스팅과 동일한 구성으로 진행하겠습니다. 페이지 넘기고 클릭하는 동적인 부분은 Selenium이, 한 페이지에서 소스 긁어오는건 BeautifulSoup이 합니다.
while 반복문 돌리면서 다음 페이지를 클릭해줄거에요. 에러나지 않도록 한 페이지 끝날마다 time.sleep 대기도 필수입니다.
그리고 한 페이지마다 BeautifulSoup으로 리뷰를 전부 긁어올게요. 긁어온 소스들은 딕셔너리에 저장해두겠습니다.
마찬가지로, 맨첫번째 제품 페이지에서 테스트 해보니 문제 없네요!
# 페이지별 소스 저장할 빈 딕셔너리 생성
soup_dict = {}
page = 1
# page에 1씩 더하면서, 전체 페이지 수와 같아지기 전까지 반복
while page < num_pages:
# 페이지별 리뷰 전부 가져오기
soup = BeautifulSoup(driver.page_source)
reviews = soup.select('ul.rvw_list li.danawa-prodBlog-companyReview-clazz-more')
time.sleep(1)
# 페이지별 리뷰 딕셔너리에 저장해두기
soup_dict[page] = reviews
print(page, "페이지 완료!")
page += 1
# 11,21,31..번째 페이지인 경우 [다음 페이지] 버튼 클릭
if page%10 == 1:
driver.find_element(By.XPATH,
'//*[@id="danawa-prodBlog-companyReview-content-list"]/div/div/a').click()
# 나머지 경우는 page에 해당하는 페이지 클릭
else:
# 페이지 넘기는 부분 경로 통째로 가져와놓고
page_nums = driver.find_element(By.XPATH,
'//*[@id="danawa-prodBlog-companyReview-content-list"]/div/div')
# 다음 페이지 링크를 클릭
page_nums.find_element(By.LINK_TEXT, str(page)).click()
# 에러나지 않도록 한페이지마다 잠시 대기
time.sleep(2)
# 마지막 페이지 리뷰 가져오고 마무리
soup = BeautifulSoup(driver.page_source)
reviews = soup.select('ul.rvw_list li.danawa-prodBlog-companyReview-clazz-more')
soup_dict[page] = reviews
print(page, "페이지 완료!")
print("<<< 테스트 크롤링 완료입니다! >>>")
2️⃣ 저장해둔 페이지 소스에서 쓸모있는 정보들만 가져와서, DataFrame에 정리해주겠습니다.
별점, 구매처, 작성일, 리뷰내용 이렇게 하나씩 가져와보겠습니다. 작성자ID는 이미 다나와에서 마스킹해둔 상태라.. 별 소용이 없을 것 같아 패스하려구요.
위 코드에 이어서 맨첫번째 제품에서만 리뷰 크롤링을 테스트 해보겠습니다. 저장해뒀던 딕셔너리에서 리뷰소스 하나씩 가져와서 데이터프레임을 생성했어요. 136개 리뷰 문제없이 저장됐습니다!
# 모델이름, 별점, 구매처, 작성일, 리뷰내용
name_list, star_list, mall_list, date_list, review_list = [], [], [], [], []
### 딕셔너리에 저장해둔 페이지 하나씩 돌리기 ###
for key in range(len(soup_dict)):
reviews = soup_dict[key+1]
# 리뷰마다 돌리면서 모델이름 등등 가져오기
for i in range(len(reviews)):
# 모델이름
try:
name_list.append(str(df_for_review_crawling['제품모델명'][0]))
except:
name_list.append('')
# 별점
try:
star_list.append(int
(reviews[i].select_one('span.star_mask').text.strip().replace('점',''))/20)
except:
star_list.append('')
# 구매처
try:
mall_list.append(str(reviews[i].select_one('span.mall').text.strip()))
except:
mall_list.append('')
# 작성일
try:
date_list.append(reviews[i].select_one('span.date').text.strip())
except:
date_list.append('')
# 리뷰내용
try:
review_list.append(str(reviews[i].select_one('div.atc').text.strip()))
except:
review_list.append('')
### 크롤링 결과 저장 ###
# 데이터프레임 생성
df_result = pd.DataFrame({
'제품모델명' : name_list, '구매처' : mall_list,
'작성일' : date_list, '별점' : star_list, '리뷰' : review_list
}); df_result
3️⃣ 최종함수를 만들어서, 공기청정기 인기제품 10개만 테스트로 크롤링해볼게요!
이전포스팅에서 수집했던 LG전자, 삼성전자, 위닉스의 공기청정기 제품들 중 일부를 선정해서 리뷰크롤링 테스트를 해봅니다.
다나와에서 검색되는 인기3사의 제품은 총 375개였는데요, 리뷰가 너무 적은 제품은 제외할게요. 리뷰가 10개도 안쌓인 제품들은 제외하고, 리뷰 10개 이상인 제품으로 걸러보니 총 239개입니다.
이걸 전부 크롤링하면 너무 오래 걸리겠어요.. 일부만 테스트해서 크롤링이 잘되는지 보고싶으니 이중에서 상위 10개 제품만 뽑아올게요.
# 필요한 패키지 가져오기
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
from datetime import datetime
import pandas as pd
import math
import pickle
from tqdm import tqdm
3️⃣-(1). [함수1] 크롬드라이버 실행부터 페이지 넘기면서 크롤링까지
이제 위에서 작성했던 코드들을 함수 2개로 묶겠습니다.
crawling_danawa_reviews_get_sources: 제품 상세페이지에 접속해서, 리뷰페이지를 넘기면서 긁어오는 함수입니다. - 입력값은 이전포스팅에서 크롤링했던 제품정보 데이터프레임입니다. - 출력값은 크롤링 페이지 소스가 전부 저장된 딕셔너리 입니다. 이렇게 수집된 데이터는 함수2에서 정리될거에요.
def crawling_danawa_reviews_get_sources(df_for_review_crawling):
# 함수 입력값: 제품정보 데이터프레임
# webdirver 설정 및 실행
my_options = webdriver.ChromeOptions()
my_options.add_argument('headless')
my_options.add_argument('--window-size=1920,1080')
my_options.add_argument("disable-gpu")
driver = webdriver.Chrome(options=my_options)
driver.implicitly_wait(1)
# 크롤링한 페이지소스 저장할 빈 딕셔너리 생성
result_dict = {}
### 제품별로 돌아가면서 상세페이지 접속 ###
for u in range(len(df_for_review_crawling)):
driver.get(df_for_review_crawling['링크URL'][u])
print(u+1, ".", df_for_review_crawling['제품모델명'][u], end=' ')
time.sleep(3)
# 제품별로 저장할 빈 딕셔너리 생성
soup_dict = {}
# 쇼핑몰 상품리뷰 개수 가져오기
soup = BeautifulSoup(driver.page_source)
num_reviews = soup.select_one('div.point_num span strong').text.strip().replace(',','')
print('-', num_reviews, '개')
# 리뷰 총 몇페이지인지 계산
num_pages = math.ceil(int(num_reviews) / 10)
### 리뷰페이지 넘기면서 페이지 소스 크롤링 및 저장 ###
# page에 1씩 더하면서, 전체 페이지 수와 같아지기 전까지 반복
page = 1
while page < num_pages:
# 페이지별 리뷰 전부 가져오기
soup = BeautifulSoup(driver.page_source)
reviews = soup.select('ul.rvw_list li.danawa-prodBlog-companyReview-clazz-more')
# 페이지별 리뷰 딕셔너리에 저장해두기
soup_dict[page] = reviews
page += 1
# 페이지 넘기는 부분 경로 통째로 가져와놓고
page_nums = driver.find_element(
By.XPATH, '//*[@id="danawa-prodBlog-companyReview-content-list"]/div/div')
# 11,21,31..번째 페이지인 경우 [다음 페이지] 버튼 클릭
if page%10 == 1:
page_nums.find_element(By.CLASS_NAME, 'point_arw_r').click()
# 나머지 경우는 page에 해당하는 페이지 클릭
else:
page_nums.find_element(By.LINK_TEXT, str(page)).click()
# 에러나지 않도록 한페이지마다 잠시 대기
print('.', end=' ')
time.sleep(2)
# 마지막 페이지 리뷰 가져오고 마무리
soup = BeautifulSoup(driver.page_source)
reviews = soup.select('ul.rvw_list li.danawa-prodBlog-companyReview-clazz-more')
soup_dict[page] = reviews
print("완료!")
result_dict[u+1] = soup_dict
# 함수 출력값: 제품별 리뷰페이지 소스 저장한 딕셔너리
return result_dict
3️⃣-(2). [함수2] 수집된 정보를 거르고 필터링해서 분석 가능한 데이터프레임으로!
crawling_danawa_reviews_result: 긁어온 데이터를 돌리면서 데이터프레임으로 정리하는 함수입니다. - 입력값은 함수1에서 크롤링 페이지 소스를 저장했던 딕셔너리, 제품정보 데이터프레임, 그리고 저장할 엑셀파일의 이름입니다. 제품정보 데이터프레임은 제품명을 가져와서 그대로 붙이기 위해 필요해요. - 출력값은 크롤링 결과가 정리된 데이터프레임, 그리고 저장된 엑셀파일입니다.
def crawling_danawa_reviews_result(result_dict, df_for_review_crawling, excel_title):
# 함수 입력값: 리뷰소스 저장된 딕셔너리, 제품정보 데이터프레임, 결과 저장할 엑셀파일명
# 제품명 풀네임, 제조사, 모델명
name_list, brand_list, model_list = [], [], []
# 별점, 구매처, 작성일, 리뷰내용
star_list, mall_list, date_list, review_list = [], [], [], []
# 제품 하나씩 돌리기
for key_p in tqdm(range(len(result_dict))):
soup_dict = result_dict[key_p+1]
# 제품명 풀네임, 제조사, 모델명 가져오기
name = df_for_review_crawling['제품모델명'][key_p]
brand = name.split()[0]
model = name.split()[-1]
# 저장해둔 리뷰페이지 하나씩 돌리기
for key_r in range(len(soup_dict)):
reviews = soup_dict[key_r+1]
# 리뷰마다 돌리면서 내용 가져오기
for i in range(len(reviews)):
# 가져와둔 제품명 풀네임, 제조사, 모델명
name_list.append(str(name))
brand_list.append(str(brand))
model_list.append(str(model))
# 별점
try:
star_list.append(int(
reviews[i].select_one('span.star_mask').text.strip().replace('점',''))/20)
except:
star_list.append('')
# 구매처
try:
mall_list.append(str(reviews[i].select_one('span.mall').text.strip()))
except:
mall_list.append('')
# 작성일
try:
date_list.append(reviews[i].select_one('span.date').text.strip())
except:
date_list.append('')
# 리뷰내용
try:
review_list.append(str(reviews[i].select_one('div.atc').text.strip()))
except:
review_list.append('')
### 크롤링 결과 저장 ###
# 데이터프레임 생성
df_result = pd.DataFrame({
'제조사' : brand_list, '모델명' : model_list, '제품명' : name_list,
'구매처' : mall_list, '작성일' : date_list, '별점' : star_list, '리뷰' : review_list
})
# 데이터프레임을 엑셀파일로 저장
with pd.ExcelWriter(excel_title) as writer:
df_result.to_excel(writer)
return df_result
제품 10개 리뷰크롤링 테스트도 성공적으로 마쳤습니다! 10개만 선정했는데도 6천개에 가까운 리뷰가 수집됐네요. 본격적으로 모든 제품의 리뷰를 수집하려면 시간이 좀 걸릴 것 같아요.
다음에는 수집한 리뷰들을 khaiii 형태소분석기로 쪼개서 워드클라우드라도 만들어볼까 합니다!