예시 데이터셋은 Kaggle에서 가져온 Flight Price Prediction 비행편 데이터셋인데요, 첫번째 칼럼은 쓸모없으니 삭제하고 출발시간(departure_time) 칼럼을 기준으로 데이터를 그룹화 시켜보았습니다.
다만 그룹핑시킨 결과를 출력해도 깔끔한 데이터셋이 나오는 건 아닙니다. 이 결과 중에 무엇을 출력할지 선택해줘야 하는데요, 하나씩 테스트 해보겠습니다.
import pandas as pd
import numpy as np
# 데이터셋 불러오기
df = pd.read_csv('./Clean_Dataset.csv', encoding='cp949')
df = df.drop('Unnamed: 0', axis=1)
# departure_time(출발시간) 칼럼 기준으로 그룹핑
dt_group = df.groupby(by='departure_time')
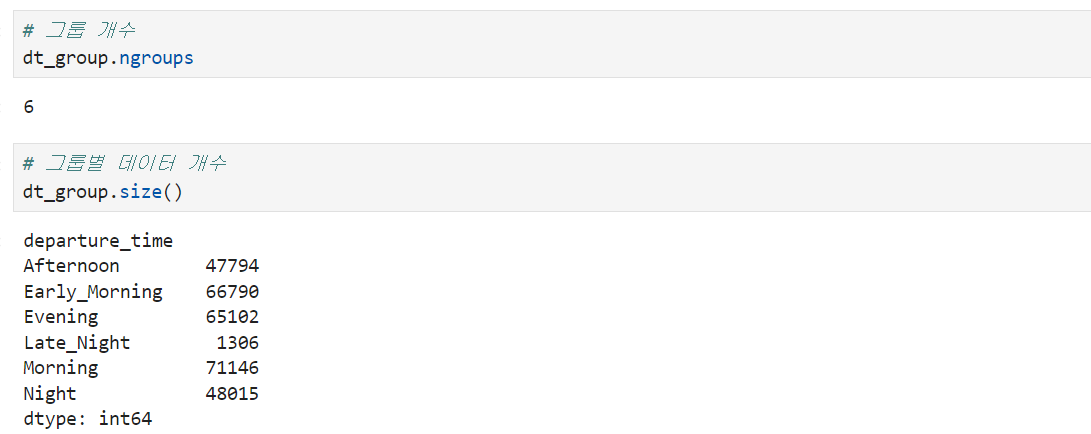
1️⃣ 그룹 개수, 그룹별 데이터 개수 :: .ngroups .size()
# 그룹 개수
dt_group.ngroups
# 그룹별 데이터 개수
dt_group.size()
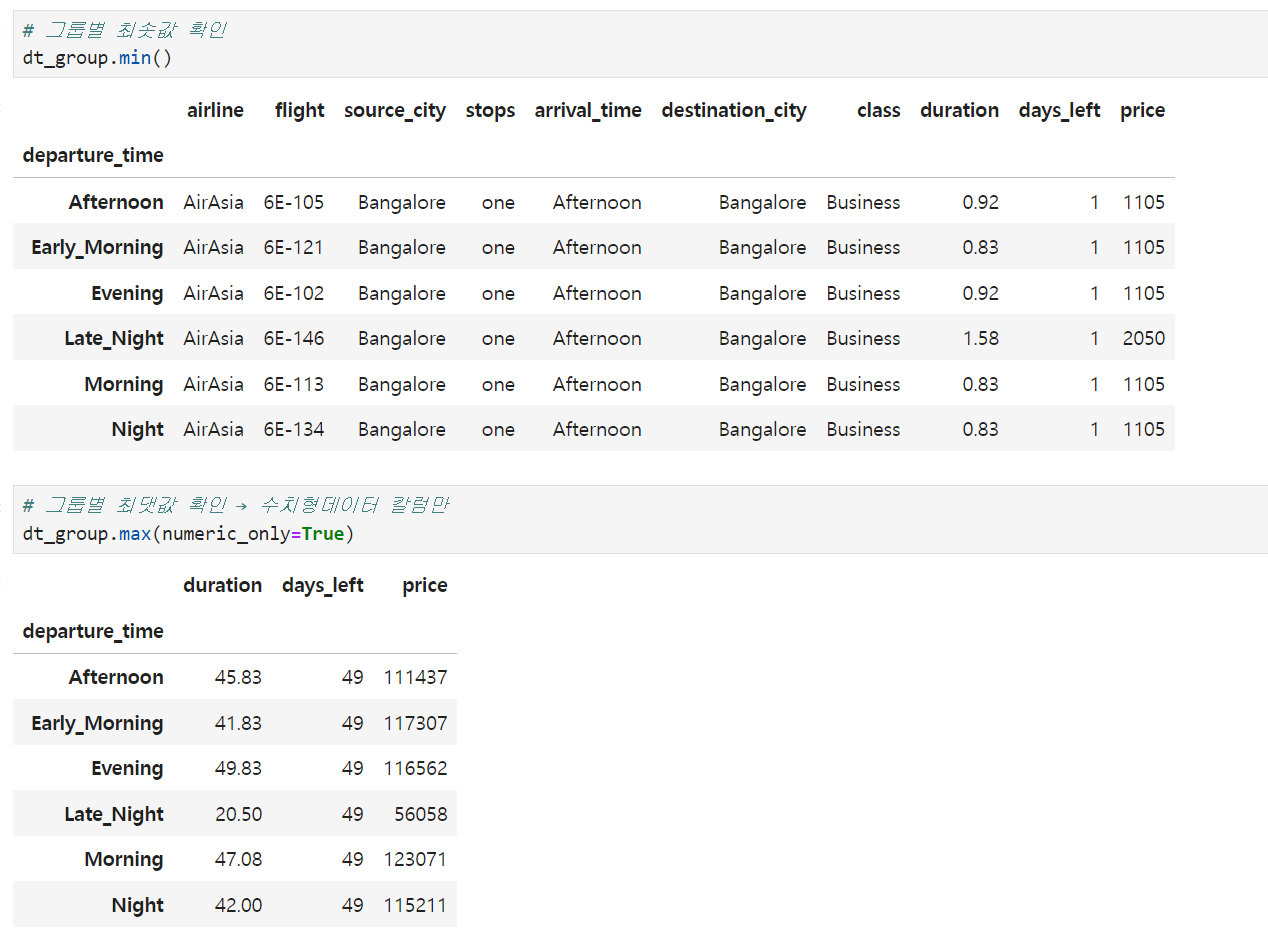
2️⃣ 그룹별 최솟값, 최댓값 출력하기 :: .min() .max()
min, max를 사용하여 그룹별 데이터의 최솟값과 최댓값을 출력할 수 있습니다.
다만 아래처럼 문자열도 알파벳 기준으로 최솟값과 최댓값을 출력해주는 모습인데요, 문자열을 제외하고 수치데이터만 보려면 numeric_only=True 파라미터를 추가하면 됩니다.
# 그룹별 최솟값 확인
dt_group.min()
# 그룹별 최댓값 확인 → 수치형데이터 칼럼만
dt_group.max(numeric_only=True)
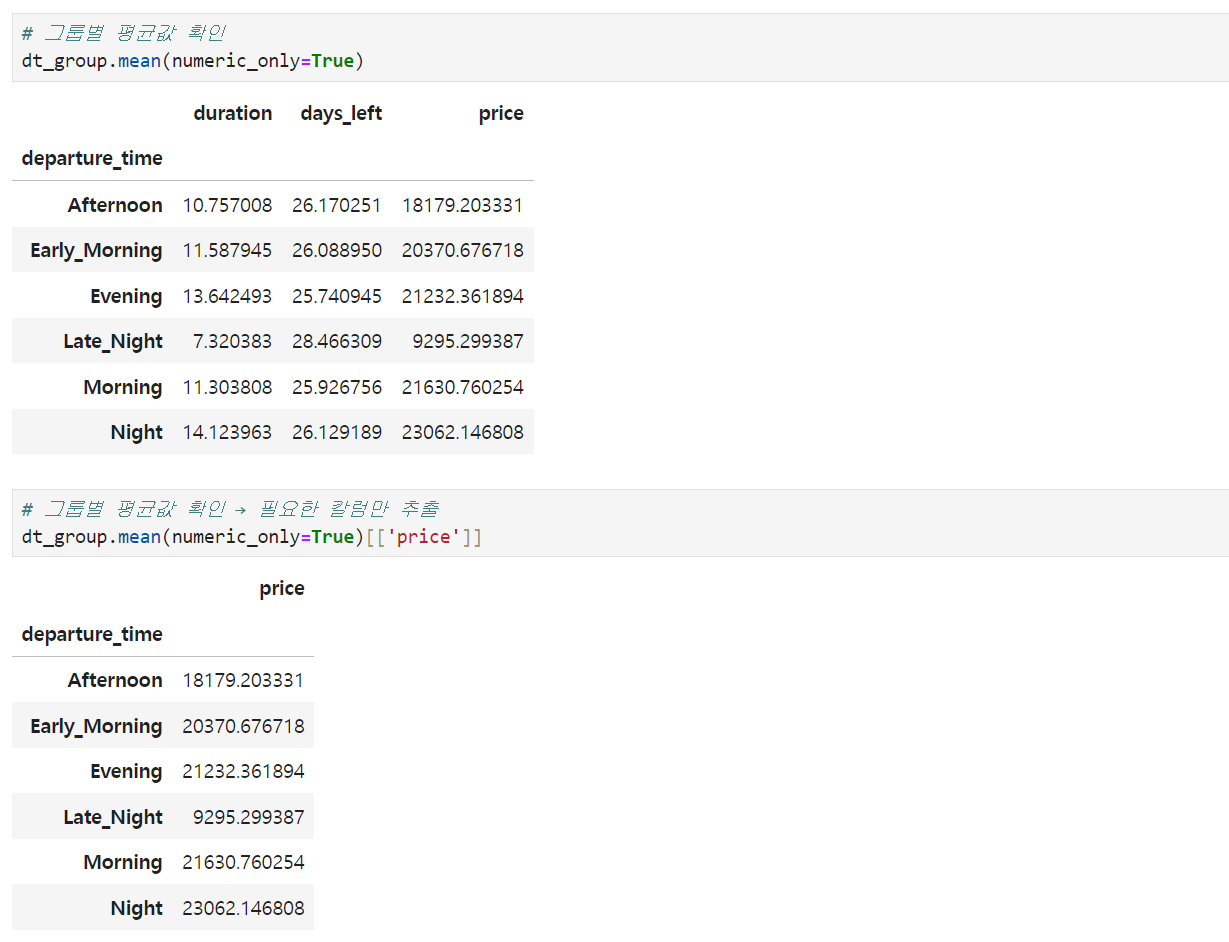
3️⃣ 그룹별 평균값, 중간값 출력하기 :: .mean() .median()
mean, median은 위의 min, max와 다르게, 문자열이 포함되어 있으니 연산할 수 없다는 에러가 나옵니다. 따라서 numeric_only=True 파라미터를 필수로 넣어줘야 합니다.
이렇게 출력한 결과에서 특정 칼럼만 추출해보고 싶다면, 데이터프레임 칼럼 뽑듯이 대괄호 2개 안에 칼럼명을 넣으면 됩니다.
# 그룹별 평균값 확인
dt_group.mean(numeric_only=True)
# 그룹별 평균값 확인 → 필요한 칼럼만 추출
dt_group.mean(numeric_only=True)[['price']]
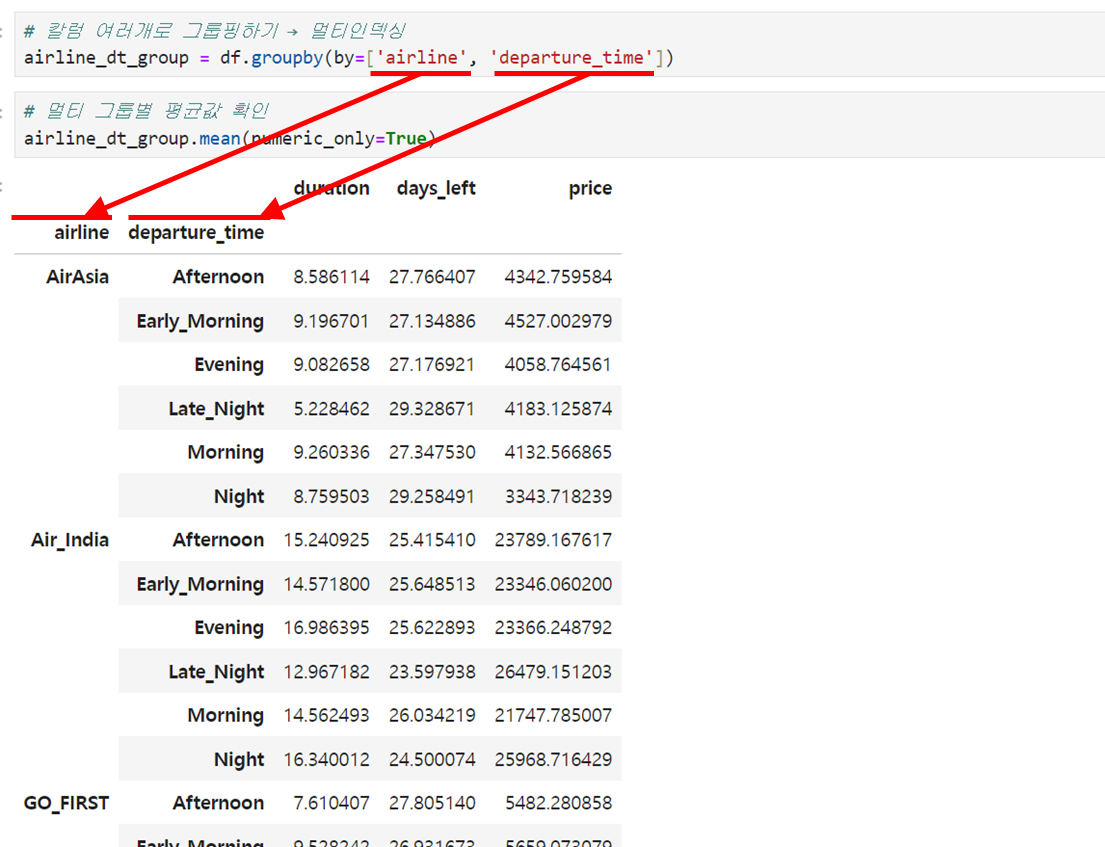
4️⃣ 칼럼 여러개로 그룹화하기 - 멀티인덱싱 (multi-indexing)
칼럼 여러개를 기준으로 그룹화 시키고 싶다면, groupby를 쓸 때 아래처럼 리스트로 칼럼을 넣어주면 됩니다. df.groupby(by=['칼럼명1', '칼럼명2'])
평균값을 출력해보면, 그룹화 기준이 된 원데이터의 칼럼 2개가 인덱스 2개로 들어가 있습니다. (멀티인덱싱)
# 칼럼 여러개로 그룹핑하기 → 멀티인덱싱
airline_dt_group = df.groupby(by=['airline', 'departure_time'])
# 멀티 그룹별 평균값 확인
airline_dt_group.mean(numeric_only=True)
인덱스가 2개 이상이면 출력한 결과도 많아집니다. 이중에서 원하는 인덱스만 선택해서 보고싶다면 일반적인 데이터프레임에서 행 뽑듯이 loc메소드를 써주면 됩니다.
만약 멀티인덱스로 행을 선택하고 싶다면, 아래처럼 튜플형식으로 넣어줘야 합니다.
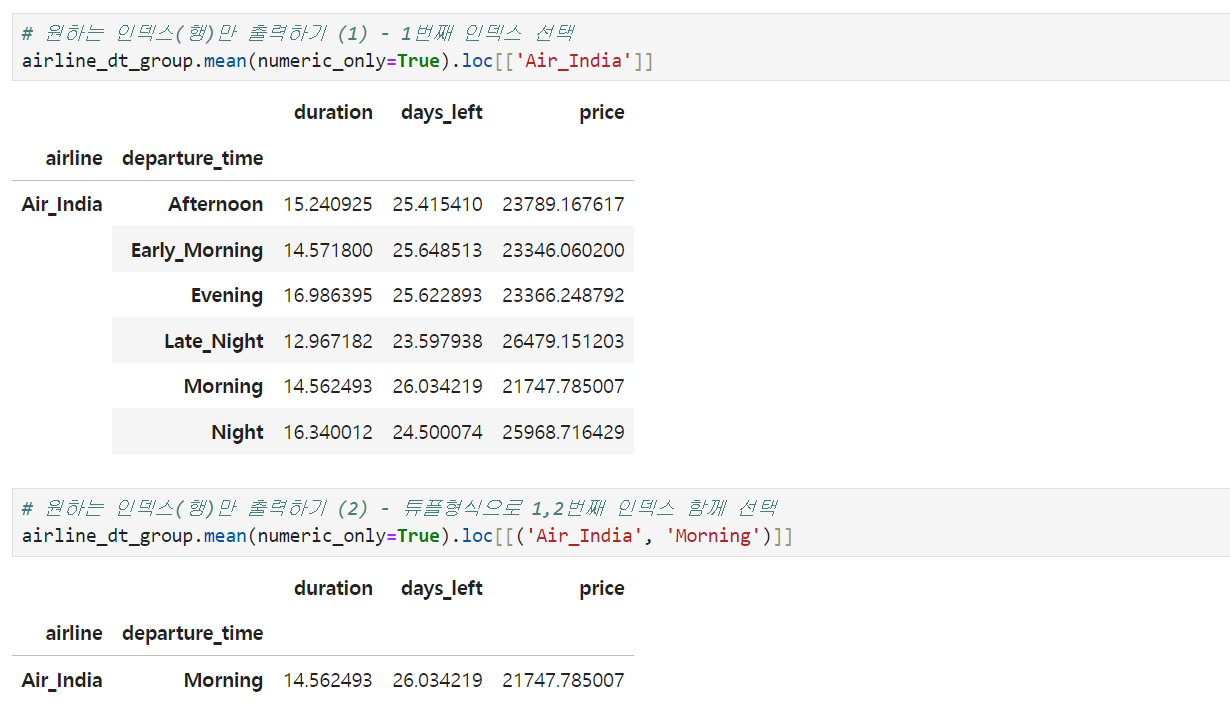
# 원하는 인덱스(행)만 출력하기 (1) - 1번째 인덱스 선택
airline_dt_group.mean(numeric_only=True).loc[['Air_India']]
# 원하는 인덱스(행)만 출력하기 (2) - 튜플형식으로 1,2번째 인덱스 함께 선택
airline_dt_group.mean(numeric_only=True).loc[[('Air_India', 'Morning')]]
5️⃣ 그룹화 결과를 여러가지 집계값으로 한번에 보기 :: aggregate
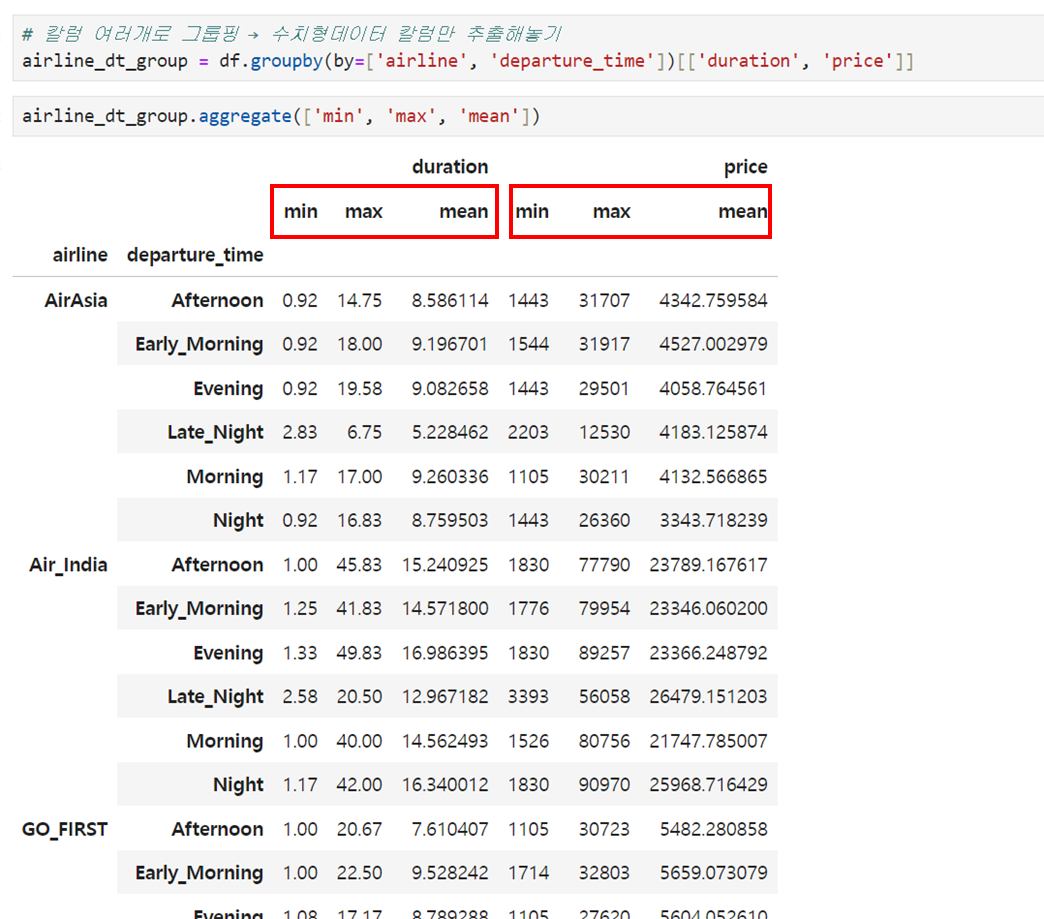
최솟값, 최댓값, 평균값.. 하나씩 뽑기보다, 보고서 작성 등을 위해 한번에 볼 수 있도록집계해야 할때, aggregate 메소드를 유용하게 활용할 수 있습니다.
위에서 멀티인덱싱 해놓았던 결과를 가지고 aggregate 테스트를 해보려고 하는데요, 살짝 귀찮은 과정이 필요합니다. aggregate는 numeric_only 파라미터가 없기 때문에 그냥 쓰면 에러가 날 수 있습니다. 아래와 같이 그룹화한 다음 수치형 칼럼만 뽑아놓고, 그 결과에서 aggregate를 써줘야 합니다.