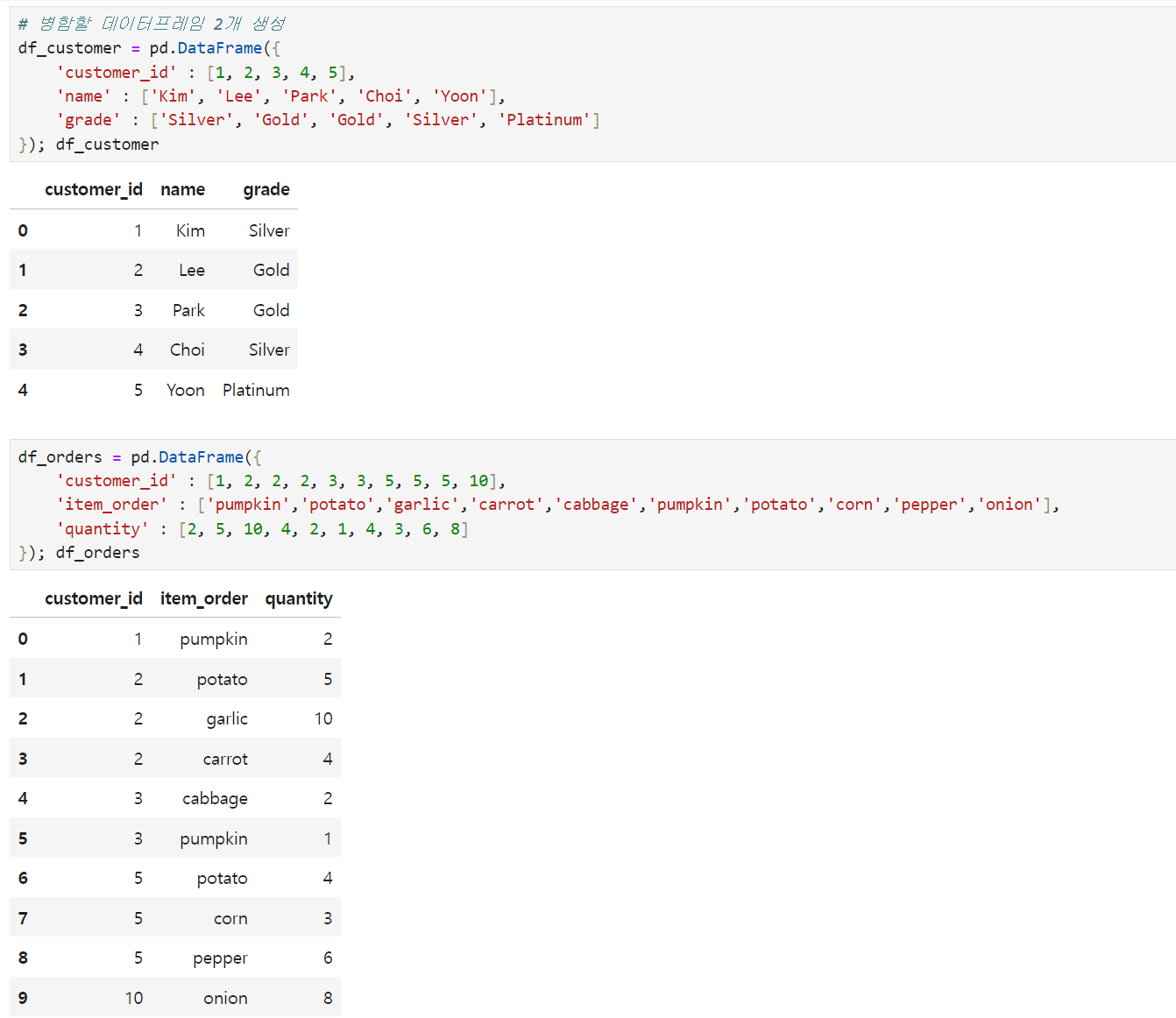
merge 메소드는 SQL JOIN 에서 문법을 가져온 메소드라는 게 눈에 보이죠. 아래와 같이 요소들을 지정해줘야 합니다. pd.merge(왼쪽에 위치할 df, 오른쪽에 위치할 df, on = '조인 기준이 되는 칼럼명', how = '조인 방식')
merge 메소드의 디폴트값이 how = 'inner' 이기 때문에, Inner Join을 하고 싶다면 아무것도 지정하지 않아도 됩니다.
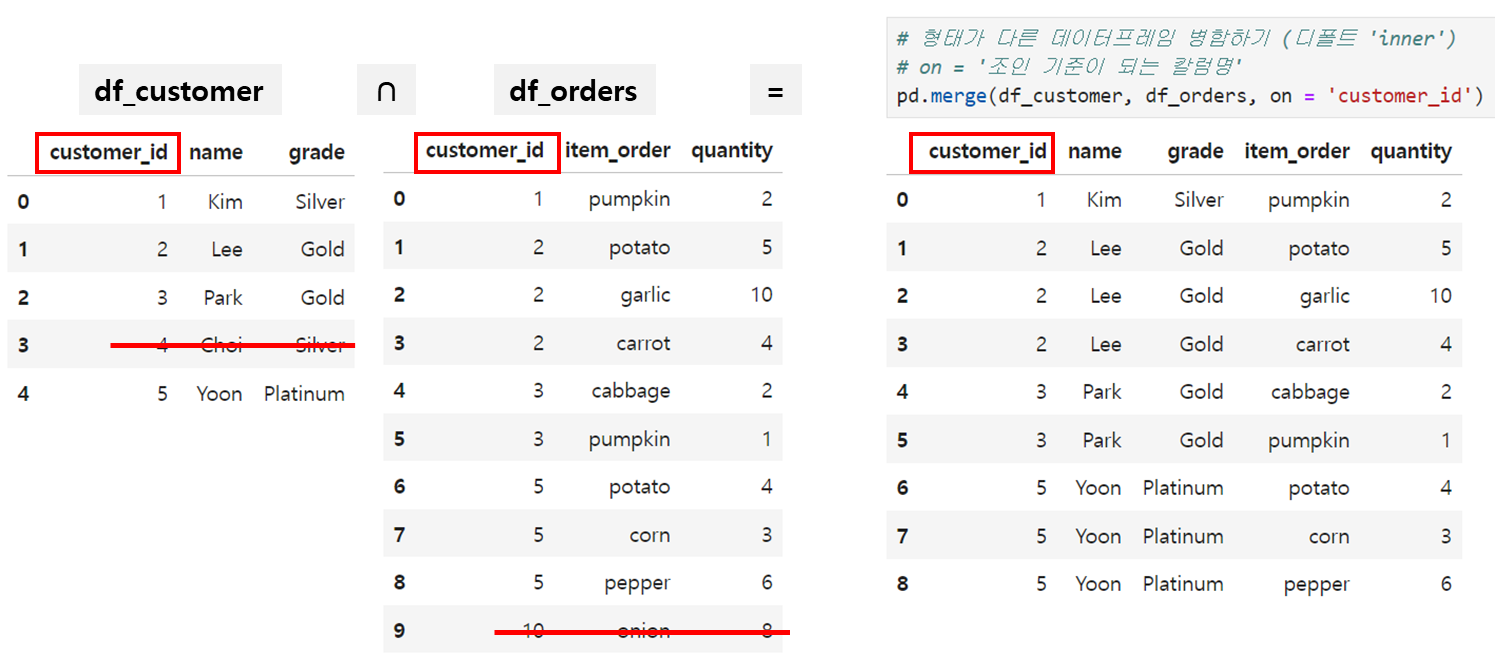
Inner Join = 교집합 방식 = 한쪽에 없는 칼럼이면 제외하고 공통으로 존재하는 칼럼만 남기는 방식입니다. 따라서 아래처럼 df_customer에만 있는 4번 고객, df_orders에만 있는 10번 고객의 구매아이템은 제외된 모습입니다.
# Inner Join 방식으로 병합하기
pd.merge(df_customer, df_orders, on = 'customer_id')
2️⃣ 합집합으로 합치기 (Outer Join)
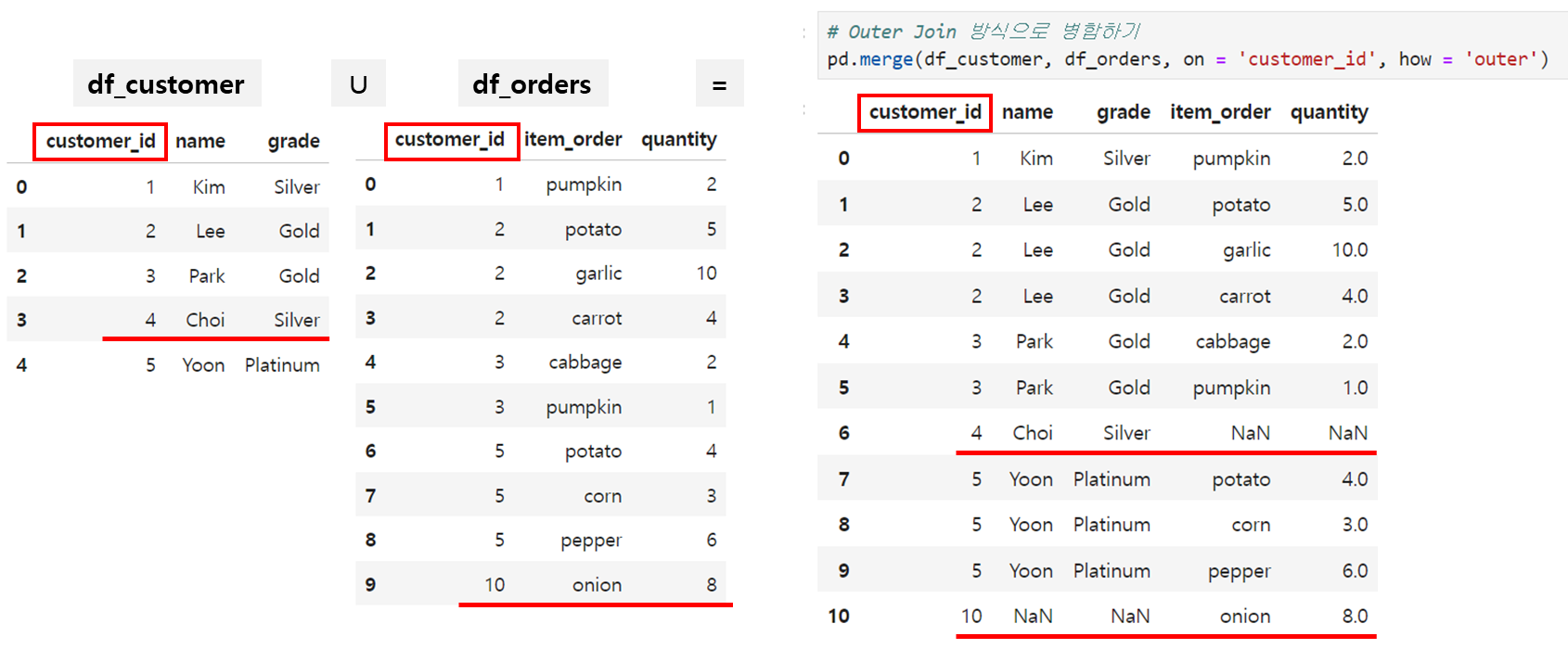
Outer Join = 합집합 방식 = 한쪽에 없는 칼럼이어도 전부 포함해서 합치는 방식입니다.
따라서 아래처럼 df_customer에만 있는 4번 고객, df_orders에만 있는 10번 고객의 구매아이템도 전부 포함되었습니다. 이에 따라 없던 셀도 생기면서 NaN값이 되었습니다. 결측치 처리된거죠.
2️⃣ 왼쪽 or 오른쪽 데이터프레임 기준으로 합치기 (Left Join, Right Join)
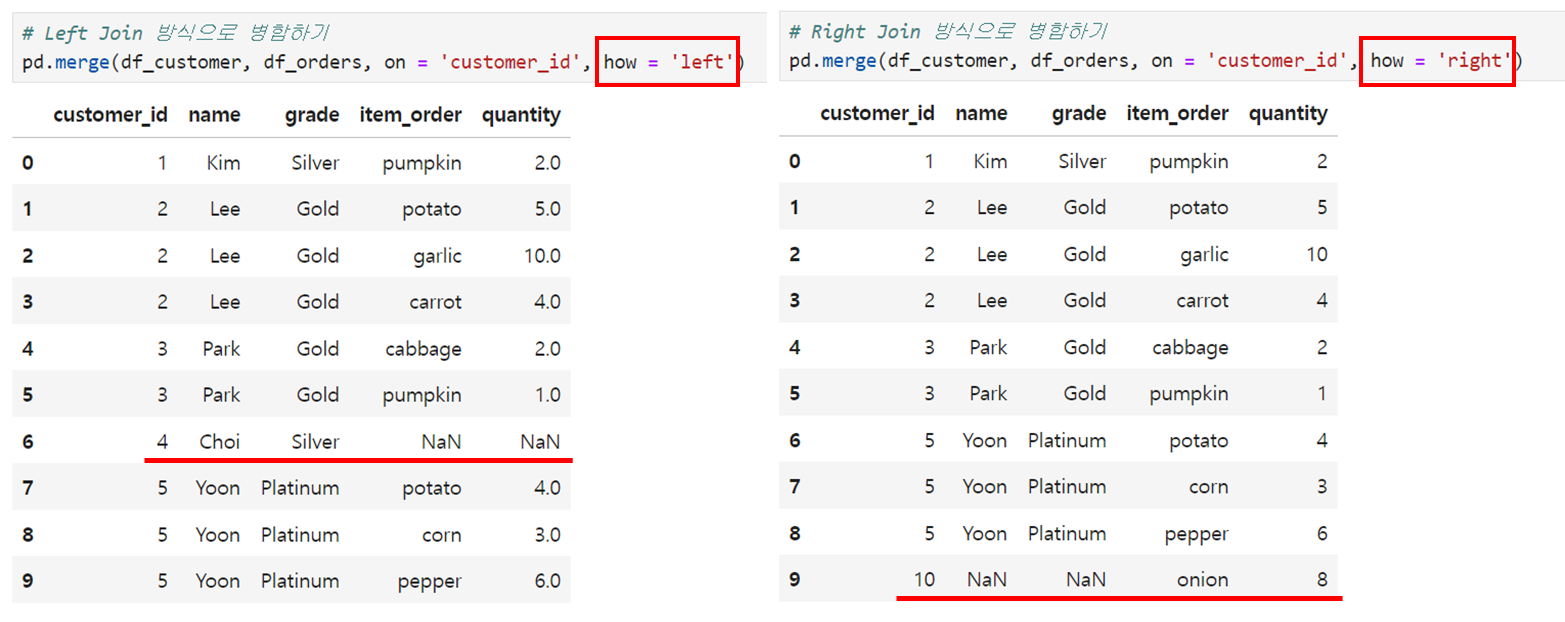
Left Join : 왼쪽 데이터프레임에 있는 건 전부 가져옵니다. 왼쪽에 없는데 오른쪽에만 존재하는 데이터는 제외합니다. 아래 예시를 보시면, df_cutomer에만 있는 4번 고객이 포함되어 있죠.
Right Join : 위와 반대입니다. 오른쪽 데이터프레임에 있는 건 전부 가져오고, 왼쪽에만 존재하는 건 제외합니다. 마찬가지로 df_orders에만 존재하는 10번 고객의 구매아이템이 포함되어 있습니다.
# Left Join 방식으로 병합하기
pd.merge(df_customer, df_orders, on = 'customer_id', how = 'left')
# Right Join 방식으로 병합하기
pd.merge(df_customer, df_orders, on = 'customer_id', how = 'right')
*️⃣ 인덱스를 기준으로 합치고 싶을 때
아래처럼, 두 데이터프레임의 인덱스를 기준으로 조인을 시킬 수도 있습니다.
이 경우 이미 인덱스를 기준으로 한다는 파라미터가 들어가므로, 파라미터 on 은 필요 없습니다. 파라미터 how를 추가해서 outer, left, right 등 조인 방식을 바꿀 수 있습니다.
# 두 인덱스를 기준으로 지정 → Inner Join과 동일
pd.merge(df_customer, df_orders, left_index = True, right_index = True)