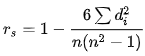군집 분석 - 여러 개의 변숫값들로부터 - 유사성(Similarity)만 기초로 - n개의 군집으로 집단화하여 - 집단의 특성을 분석하는 - 다변량 분석기법
군집 분석 종류: 계층적 군집/ k-평균 군집/ 혼합 분포 군집/ 자기 조직화 지도(SOM)
계층적 군집: 군집 개수 미리 정하지 않음 ⇒ 병합적 방법/ 분할적 방법/ 덴드로그램
비계층적 군집: 군집 개수 k 미리 정함 ⇒ k-평균 군집/ 혼합 분포 군집/ 자기 조직화 지도
(2) 계층적 군집 (Hierarchical Clustering) | 유사한 개체들의 군집화 과정 반복
군집 형성 방법: 병합적 방법/ 분할적 방법
병합적 방법 (Agglomerative): 작은 군집 → 병합 - 거리 가까우면 유사성 높음 - R : {stats} hclust(), {cluster} agnes(), mclust()
분할적 방법 (Divisive): 큰 군집 → 분리 - R : {cluster} diana(), mona()
군집 결과 표현: 계통도/ 덴드로그램
덴드로그램(Dendrogram): 군집의 개체들이 결합되는 순서를 나타내는 트리 구조
항목간 거리/ 군집간 거리/ 군집내 항목간 유사도/ 군집의 견고성 파악 가능!
각 개체는 한 군집에만 속함
군집간 거리 측정 방법/ 연결법: 최단연결법/ 최장연결법/ 중심연결법/ 평균연결법/ 와드연결법
최단연결법 = 단일연결법: 두 군집간 거리 = 최솟값 으로 측정 - 각 군집에서 한 개체씩 뽑았을 때 나타날 수 있는 최솟값을 군집간 거리로 측정함
최장연결법 = 완전연결법: 두 군집간 거리 = 최댓값 으로 측정 - 각 군집에서 한 개체씩 뽑았을 때 나타날 수 있는 최댓값을 군집간 거리로 측정함
중심연결법: 두 군집 중심 사이 거리 측정 - 두 군집 결합 → 가중평균으로 새로운 군집의 평균 구함 - 군집 내 편차 제곱합 고려 → 군집간 정보 손실을 최소화
평균연결법: 모든 개체에 대한 거리 평균 구하면서 군집화 - 계산량이 불필요하게 많아질 가능성..
와드연결법: 군집내 오차 제곱합 기반으로 군집화 - 다른 연결법들은 군집간 거리에 기반하는데, 와드연결법은 군집내 거리를 기반으로 함
군집간 거리 계산: 연속형/ 명목형/ 순서형 변수마다 거리 계산 방법 다름~
연속형 변수 거리: 유클리드/ 맨하튼/ 민코프스키/ 표준화/ 마할라노비스 거리 - 유클리드 거리: 두 점을 잇는 가장 짧은 직선 거리 - 맨하튼 거리(시가 거리): 각 방향 직각의 이동 거리 합 - 민코프스키 거리: 1차원일 때 맨하튼 거리, 2차원일 때 유클리드 거리와 같음 - 표준화 거리: 각 변수를 표준편차로 변환한 후, 유클리드 거리를 계산 - 마할라노비스 거리: 변수들의 산포를 고려하여 표준화한 거리 변수의 표준편차 고려/ 변수간 상관성이 있으면 표준화 거리 사용 검토해야 함
명목형 변수 거리: 단순 일치 계수/ 자카드 계수 - 모든 변수가 명목형인 경우, (두 개체간 다른 값을 가지는 변수의 수)를 (총 변수의 수)로 나눈 것이 거리임 - 자카드 계수는 두 집합이 같으면 1, 공통 원소가 없으면 0
순서형 변수 거리: 순위상관계수
연속형 변수 거리
수학적 거리
통계적 거리
유클리드 거리
맨하튼 거리
민코프스키 거리
표준화 거리
마할라노비스 거리
제곱합의 제곱근
절댓값의 합
m차원 민코프스키 공간에서의 거리
측정단위 표준화
표준화+상관성 동시에 고려함
D: 표본 분산(대각)행렬
S: 표본 공분산 행렬
명목형 변수 거리
순서형 변수 거리
단순 일치 계수
자카드 계수
순위상관계수
전체 중 일치하는 속성의 비율
두 집합간 유사도 측정 (0~1)
값에 순위 매김 → 상관계수 계산
(매칭된 속성 개수) / (전체 속성 개수)
(3) k-평균 군집 (k-means clustering) | k 개의 군집 묶음 → 군집 평균 재계산 → 반복
k-평균 군집: 주어진 데이터를 k개의 군집으로 묶는 알고리즘 - 초기 군집을 k개 지정하고, - 각 개체를 가까운 군집에 할당하여 군집을 형성한 다음, - 각 군집 평균을 재계산하고, - 군집 갱신을 반복하여 - k개의 최종 군집을 형성한다!
절차: k개 객체 선택 → 할당 → 중심 갱신 → 반복
k개 객체 선택: 초기 군집의 중심으로 삼을 객체 k개를 랜덤 선택
할당 (Assignment): 각 객체들을 가장 가까운 군집의 중심에 할당
중심 갱신 (New Centroids): 각 군집별로 평균 계산 → 군집 중심 갱신
반복: 군집 중심의 변화가 거의 없을 때까지/ 최대 반복수에 도달할 때까지 할당과 중심 갱신을 반복
단점: 이상값에 민감 → k-중앙값 군집 or 이상값 미리 제거
(4) 혼합 분포 군집 (Mixture Distribution Clustering) | 모수적 모형 기반 군집화 방법
혼합 분포 군집 - 데이터가 k개의 모수적 모형의 가중합으로 표현되는 - 모집단 모형에서 나왔다는 가정 하에 - 데이터로부터 모수 & 가중치를 추정하는 방법
k개의 모형 = k개의 군집 을 의미함
군집화 방법: - 추정된 k개의 모형(군집)들 중에서, - 어느 모형에서 나왔을 확률이 높은지에 따라서 - 각각의 데이터를 군집으로 분류한다!
혼합모형 = M개 분포(성분)의 가중합 - 단일모형과 비교하면, 혼합모형은 표현식이 복잡! - 따라서 미분을 통한 이론적 전개가 어려움 - 최대가능도 추정을 위해 EM알고리즘을 활용함
EM 알고리즘 (Expectation-Maximization Algorithm, 기댓값 최대화 알고리즘) - 관찰/측정되지 않은 잠재변수에 의존하는 확률모델에서 - 최대 가능도나 최대 사후 확률을 가지는 - 모수의 추정값을 찾는 반복적인 알고리즘
(︶^︶) 최대 가능도 (Maximum Likelihood) 란, 어떤 모수가 주어졌을 때,
원하는 값들이 나올 가능도를 최대로 만드는 모수를 선택하는 방법을 말한다.
진행과정: E-step → M-step
E-step: 잠재변수 Z의 기대치 계산
M-step: 기대치 이용하여 파라미터 추정
반복: M-step에서 계산된 값은 다음 E-step에서 추정값으로 쓰임
특징
확률분포 도입하여 군집화
군집을 모수로 표현
서로 다른 크기의 군집 찾을 수 있음
데이터 커지면 → 수렴 시간 걸림
군집 크기 너무 작으면 → 추정 정도 떨어짐
이상값 민감 → 사전 조치 필요!
(5) 자기 조직화 지도 (SOM; Self-Organizing Maps): 비지도 신경망 클러스터링
자기 조직화 지도
대뇌피질, 시각피질의 학습과정을 기반으로 모델화한 인공신경망
자율학습방법에 의한 클러스터링 방법을 적용한 알고리즘
고차원 데이터를 이해하기 쉬운 저차원 뉴런으로 정렬 → 지도로 형상화한 비지도 신경망
구성: 입력층/ 경쟁층
자기 조직화 지도 = SOM = 코호넨 맵(네트워크)
입력층 (Input Layer)
경쟁층 (Competitive Layer)
- 입력벡터 받는 층 - 입력변수 개수 = 입력층 뉴런 개수 - 입력층 각 뉴런과 경쟁층 각 뉴런은 완전연결되어 있음
- 입력벡터 특성에 따라, 벡터 한 점으로 클러스터링되는 층 - 2차원 m ⨉ m 그리드(격자)로 구성된 층 - 지도(Map): 입력층 → 학습 → 경쟁층에 정렬됨
특징: 입력변수의 위치관계를 그대로 보존하여 형상화 → 실제 공간에 가까이 있으면 지도상에도 가까운 위치!
학습과정: 경쟁학습/ 승자독식구조
경쟁학습: 경쟁층의 각 뉴런이 입력벡터와 얼마나 가까운지 계산 → 연결강도를 반복적으로 재조정하여 학습 → 입력패턴과 가장 유사한 경쟁층 뉴런이 승자!
승자독식구조: 경쟁층에 승자 뉴런만 나타남 → 승자와 유사한 연결강도를 가지는 입력패턴이 동일한 경쟁 뉴런으로 배열됨
연결강도 초기화 → 입력벡터 제시 → 유사도 계산 → 프로토타입 벡터 탐색 → 연결강도 재조정 → 반복 - 프로토타입 벡터 탐색: 입력벡터와 가장 가까운 뉴런인 BMU(Best Matching Unit)을 탐색하는 단계